使用maven集成java和scala开发环境 |
您所在的位置:网站首页 › maven dependency plugin配置 › 使用maven集成java和scala开发环境 |
使用maven集成java和scala开发环境
|
使用maven集成java和scala开发环境
创建项目增加scala依赖创建目录安装scala插件scala的hello worldmaven 插件配置仓库maven-compile-pluginmaven-scala-pluginmaven-jar-pluginmaven-dependency-pluginmaven-assembly-plugin
spark 开发环境
git地址:https://gitee.com/jyq_18792721831/sparkmaven.git
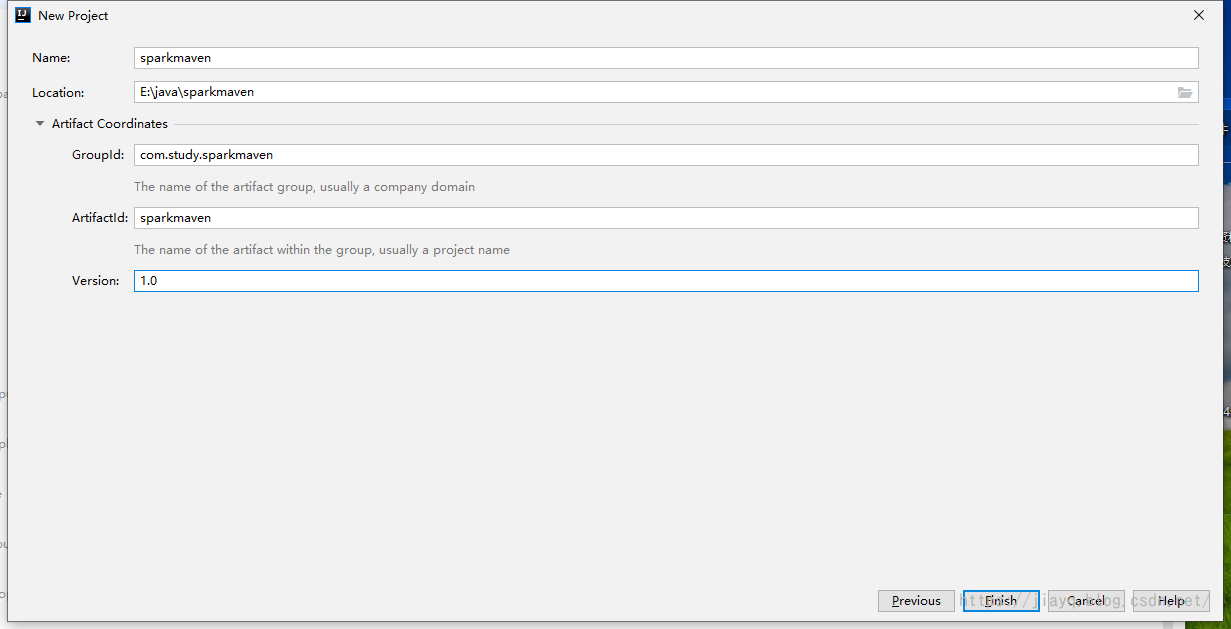
创建项目
我们首先创建一个普通的maven项目
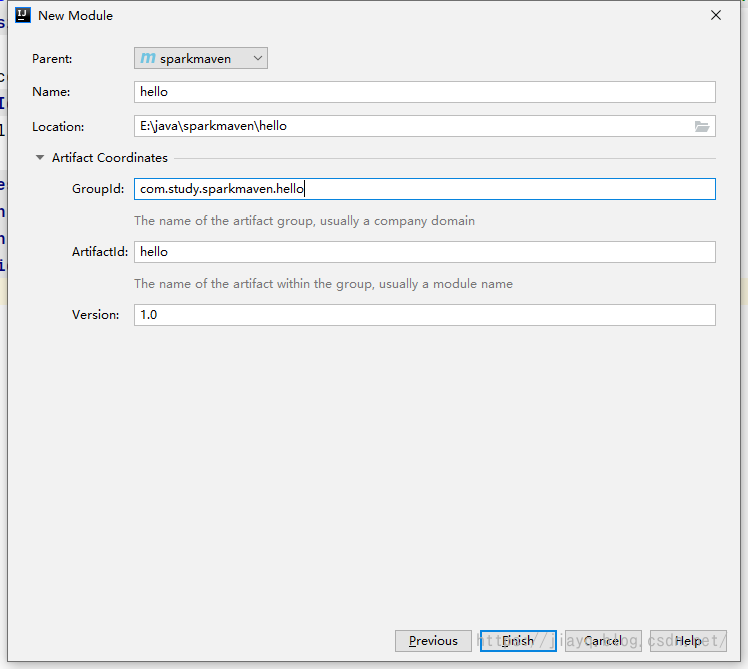
创建项目后接着创建一个hello的模块
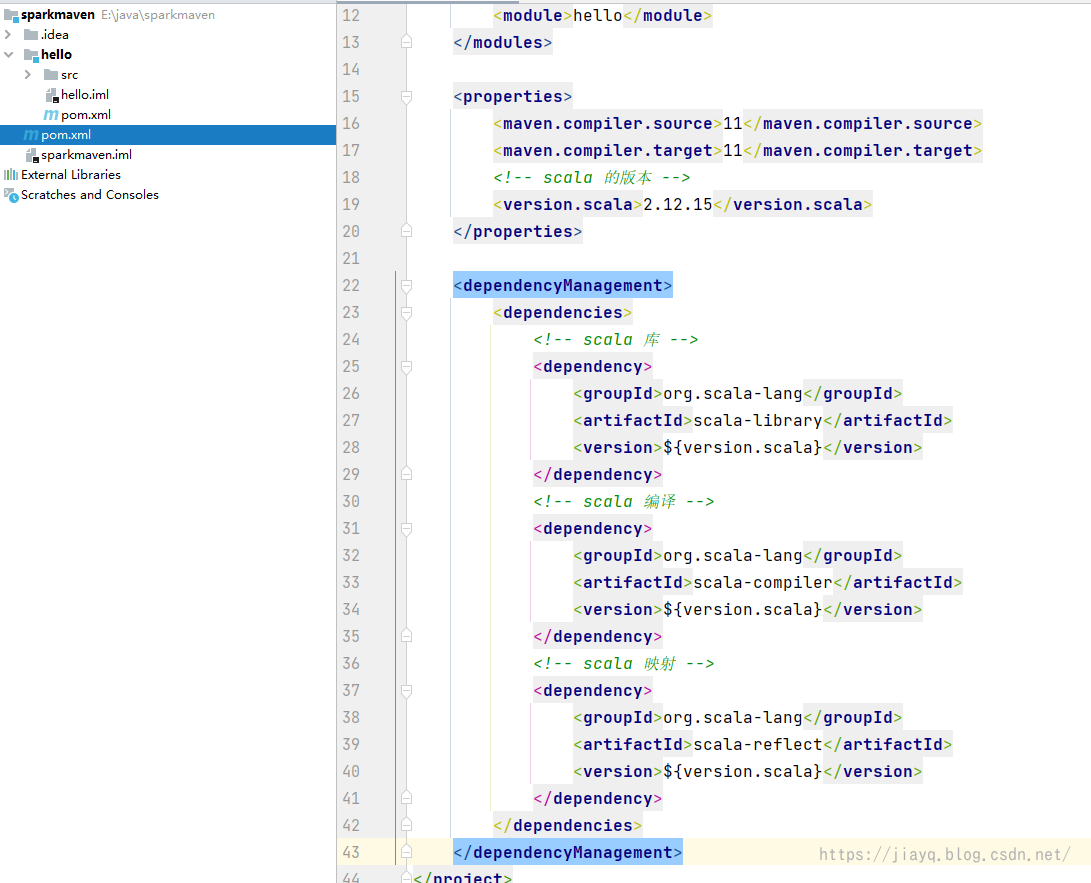
也是普通的maven模块 增加scala依赖我们在父项目中是不会写代码的,父项目只是为了管理子项目的,所以父项目的src目录可以删除 我们在父项目的pom.xml中增加依赖
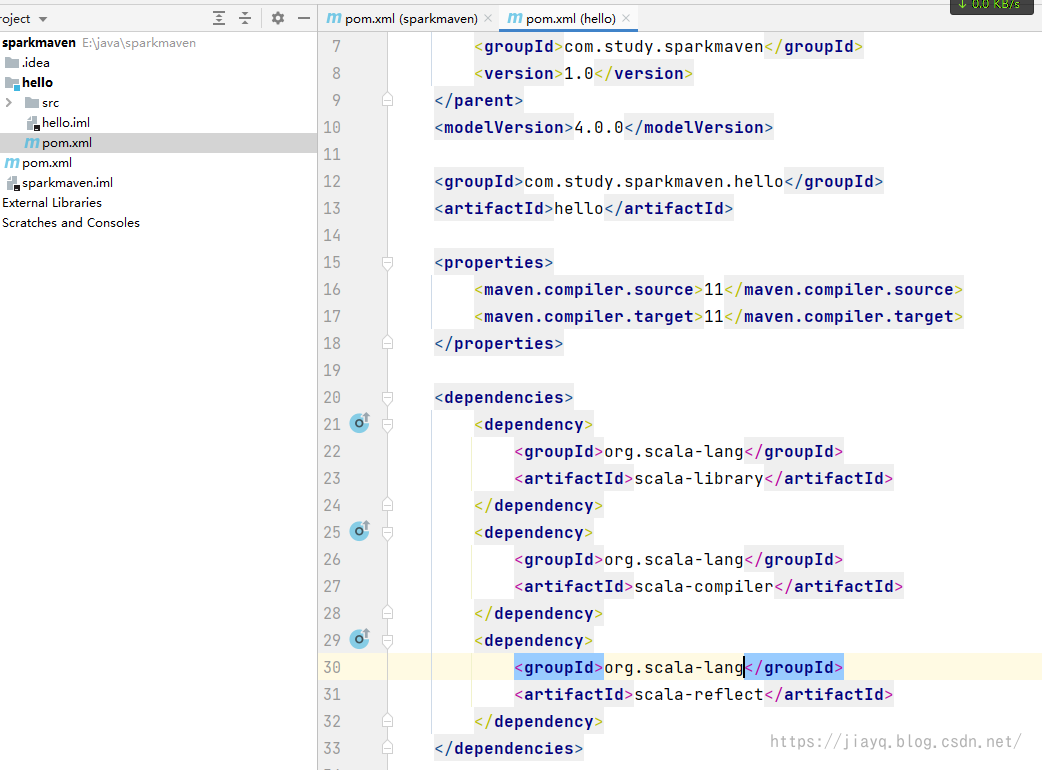
如下 4.0.0 com.study.sparkmaven sparkmaven pom 1.0 hello 11 11 2.12.15 org.scala-lang scala-library ${version.scala} org.scala-lang scala-compiler ${version.scala} org.scala-lang scala-reflect ${version.scala}接着在hello模块的pom.xml中将scala相关的依赖引入
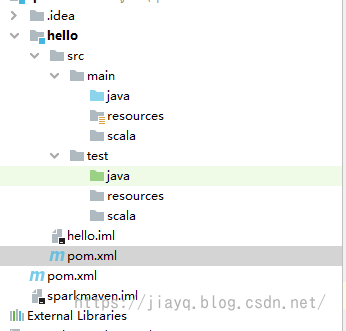
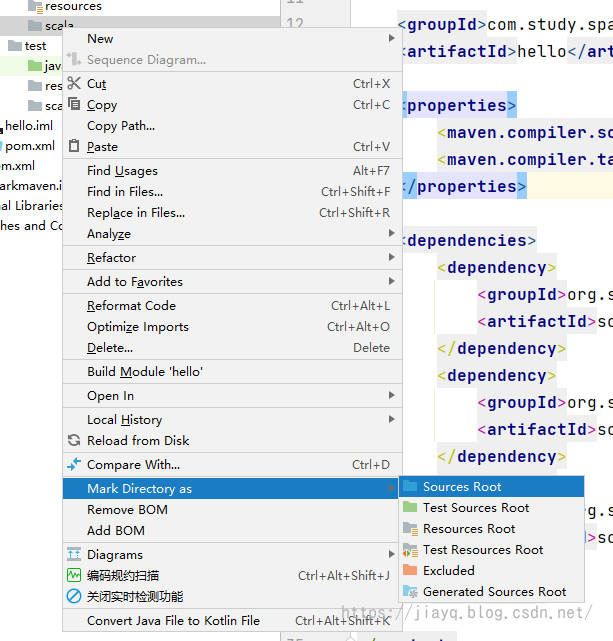
我们需要在src目录下创建我们的源码目录和资源目录
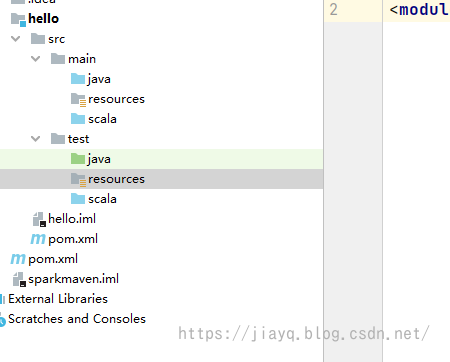
并使用右键标注为源码和资源
标注完成后如下
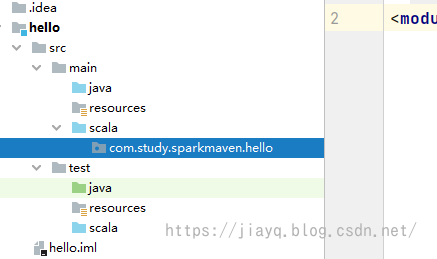
接着创建我们的包目录
首先打开设置
在插件处查询scala插件并安装,可能需要多试几次
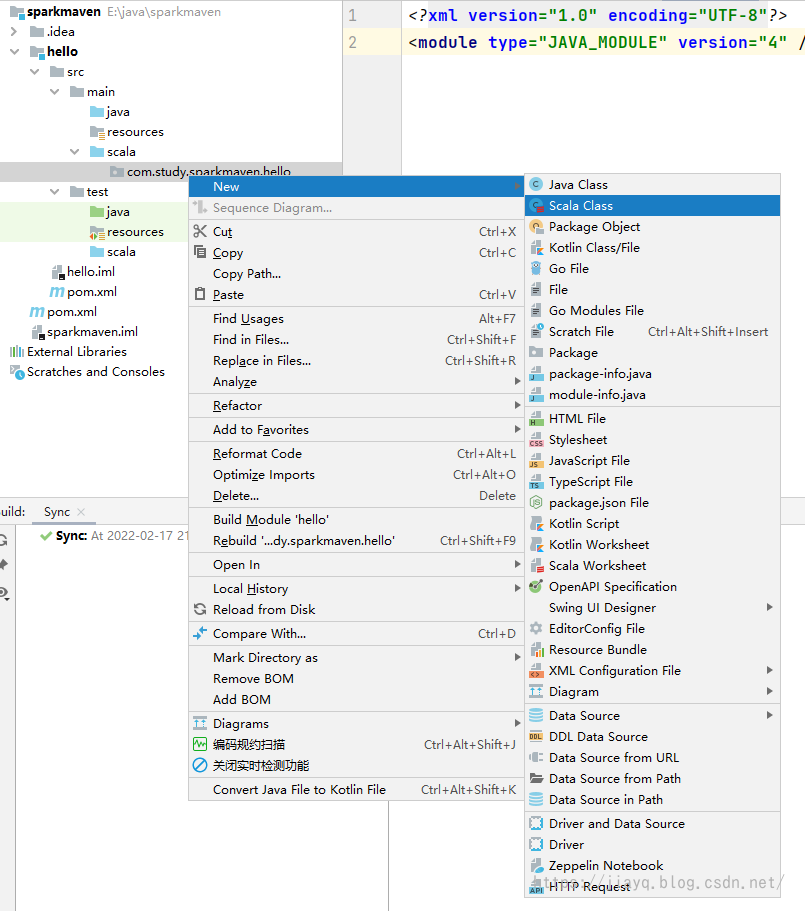
而且scala插件比较大的,下载不一定能一次成功。如果确实无法下载,可以去idea的插件市场中离线下载,然后离线安装。 scala的hello world我们在scala的源码下进行开发 此时在新建文件的时候,是找不到scala的选项的
我们刷新整个maven项目,让maven下载依赖
当然,刷新完还是无法创建scala的项目
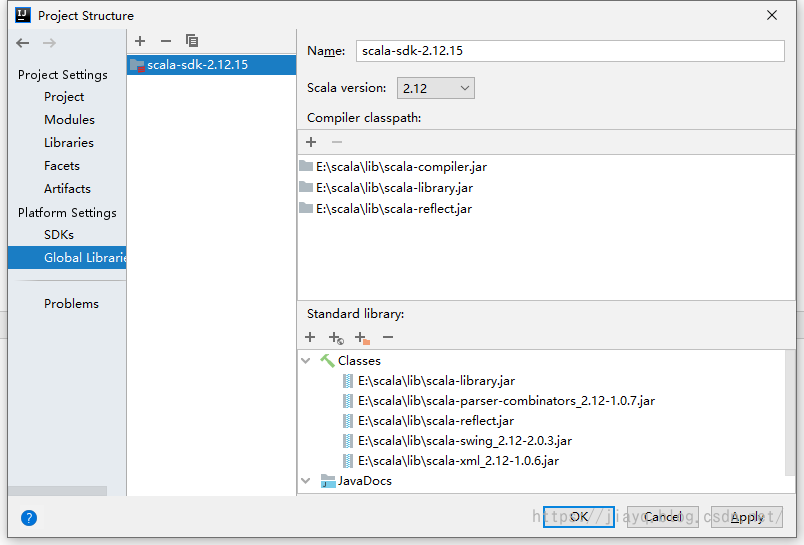
我们需要告诉idea,我们的项目需要支持scala,所以我们需要把scala的sdk加入
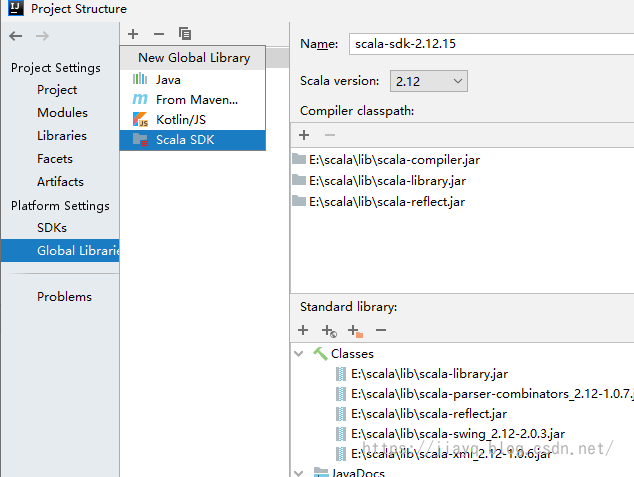
首先保证你的全局的sdk有scala,如果没有需要点击+增加
比如
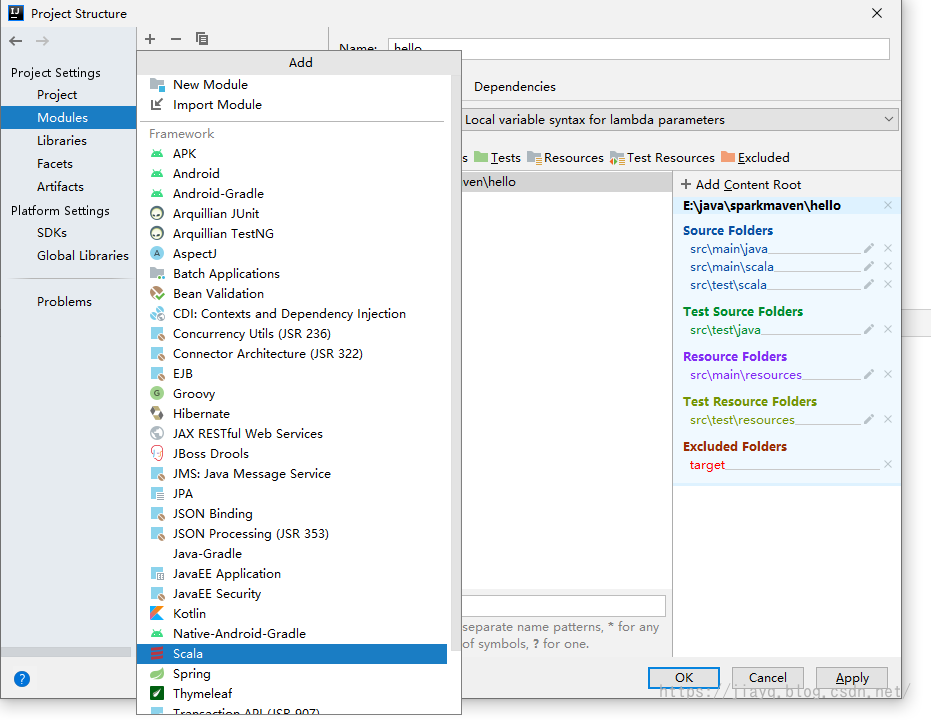
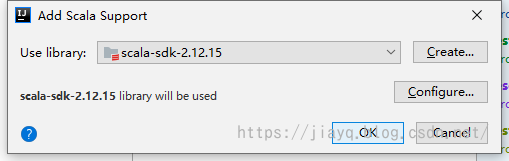
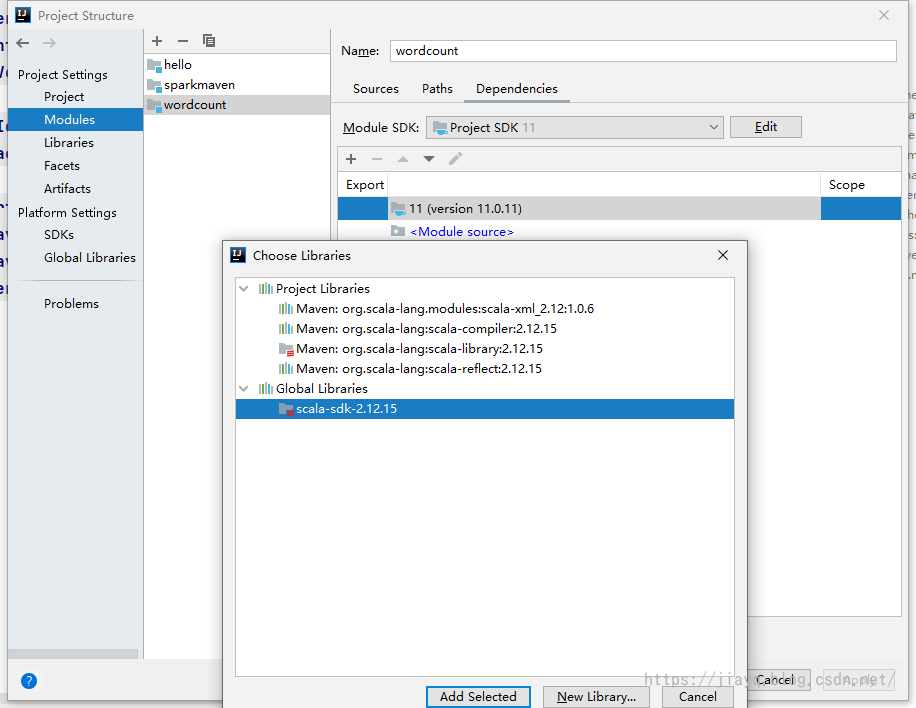
当然,最最前提是你需要安装scala的插件,只有安装了scala的插件,才能开发与scala有关的内容。 我们在模块设置将scala加入
选择我们的scala版本的sdk,如果你有多个版本的scala的sdk,一定注意版本
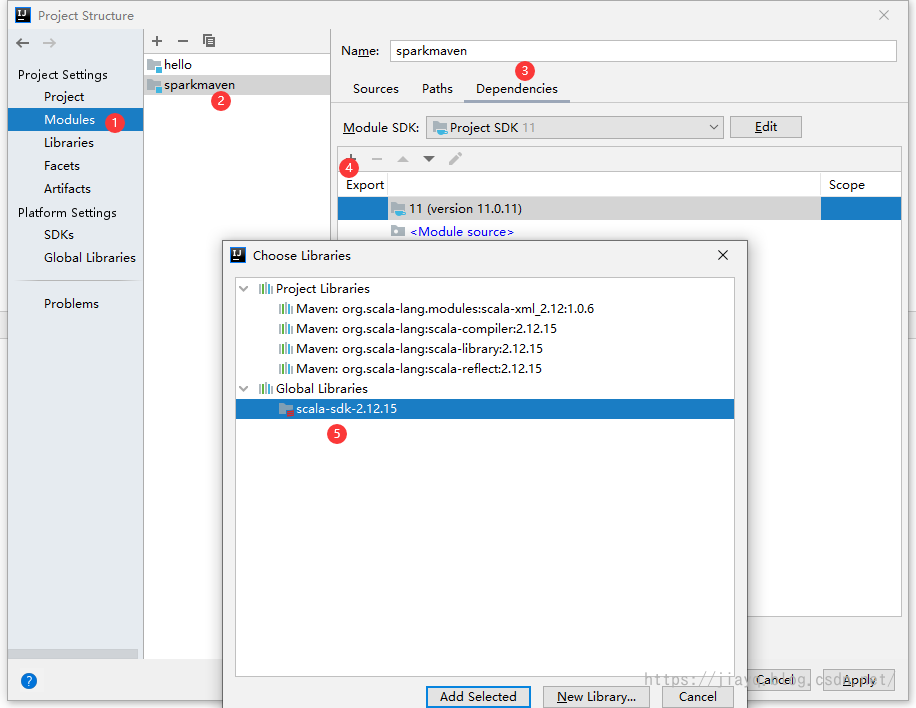
我们也可以把scala的sdk加入到根项目中
当然,你在加入到根项目中后,在子项目中还是需要增加一次 我们这里增加实际上与maven增加scala的依赖是没有任何冲突的 我们在这里增加依赖,只是告诉idea,在我们的项目中需要用到scala的一些功能而已
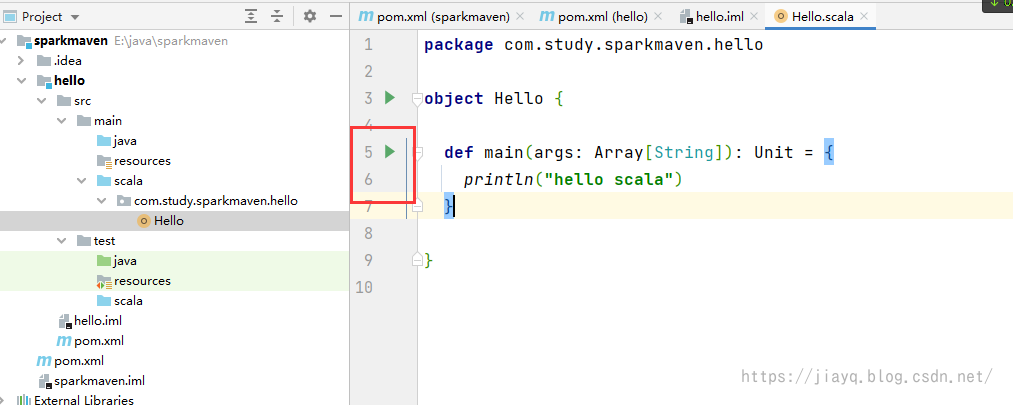
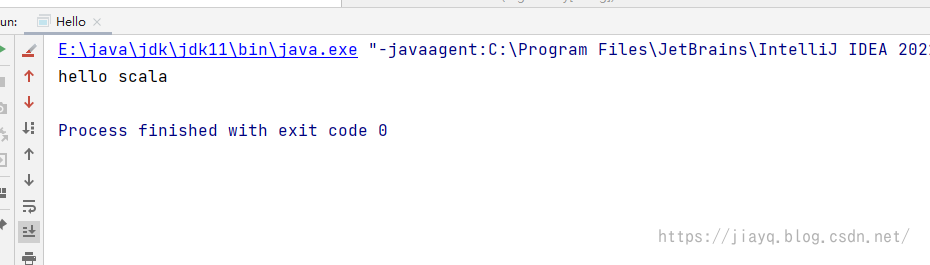
我们选择增加一个object,写如下内容 package com.study.sparkmaven.hello object Hello { def main(args: Array[String]): Unit = { println("hello scala") } }然后点击运行
如下
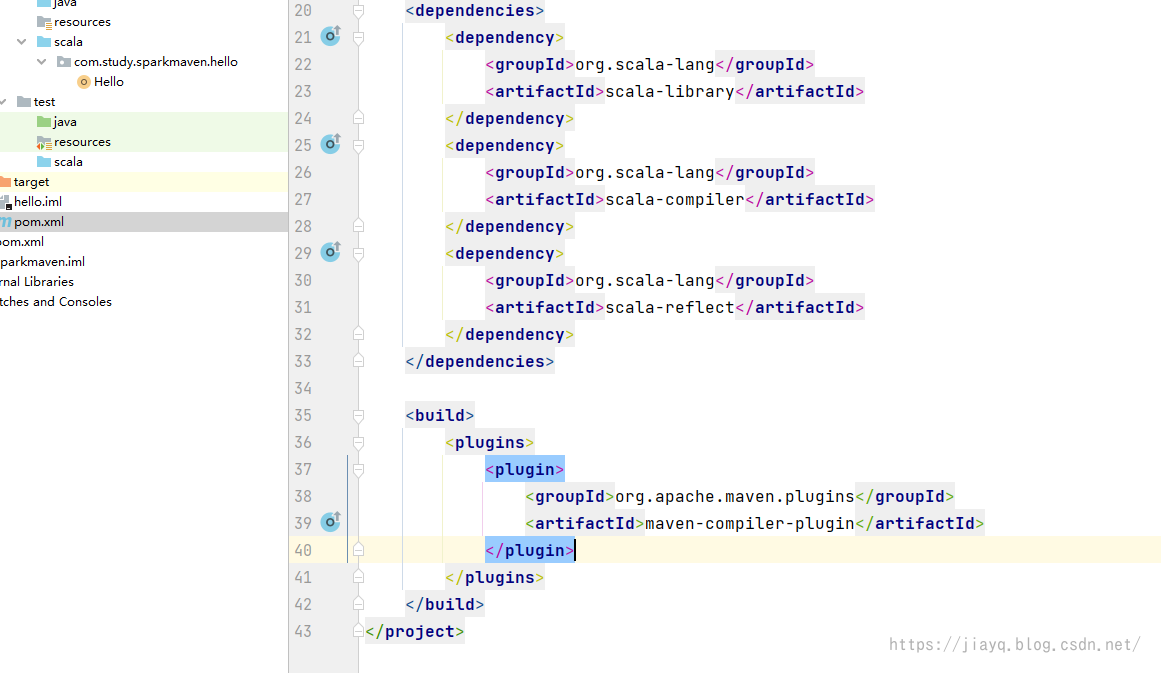
我们虽然开发了scala的hello world,但是这没啥意义,只是说明我们的idea目前支持了scala的语法,我们还需要安装一些maven的插件,用于帮助我们做其他的处理。 还是和依赖一样的管理方式,我们在父项目的pom.xml中定义依赖和插件,包括一些插件的通用配置,然后在子项目中增加子项目个性化的依赖,以及子项目个性化的插件配置。 约定所有的版本号都在properties中统一配置。 插件都在build-pluginManage-plugins下配置 配置仓库如果不配置仓库,默认是从maven的中央仓库下载依赖和插件,会比较慢,我们可以配置国内镜像,加快下载速度 maven-net-cn Maven China Mirror http://maven.aliyun.com/nexus/content/repositories/central/ central Maven China Mirror http://maven.aliyun.com/nexus/content/repositories/central/我们在父项目的pom.xml中配置即可。 maven-compile-plugin我们在父项目的pom.xml中加入maven-compile-plugin插件 首先定义插件的版本 11 11 2.12.15 3.9.0接着配置插件 org.apache.maven.plugins maven-compiler-plugin ${version.maven.compile.plugin} ${maven.compiler.source} ${maven.compiler.target} UTF-8 true或许你可能会比较疑惑,我们怎么知道我可以使用哪些插件,以及这些插件的版本是什么呢? 你可以在Maven – Available Plugins (apache.org)查询所有可用的插件,点击插件名字可以进入到插件的文档界面,里面会有详细的版本号,以及如何使用等信息
详细信息
千万记得,我们在父项目中配置插件后,还需要在子项目中引入 我们在hello项目的pom.xml中引入
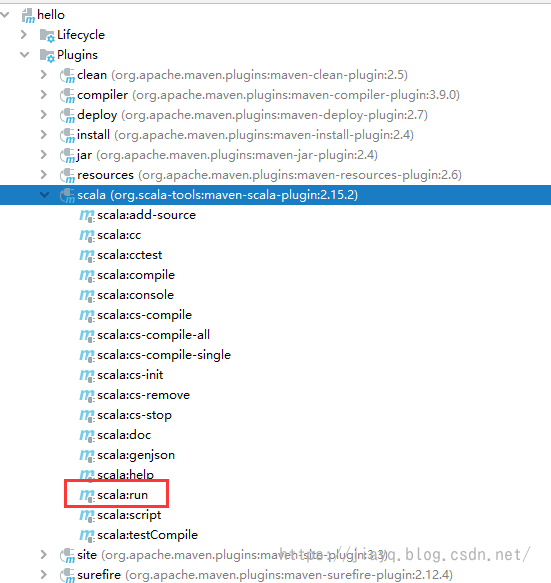
这样做的好处是在一个pom.xml中统一管理项目中的插件的版本等信息。一些通用的配置也可以在父项目的pom.xml中配置。 maven-scala-plugin我们接着配置scala的插件 定义版本 2.15.2接着引入和配置插件 org.scala-tools maven-scala-plugin ${version.maven.scala.plugin} ${version.scala} scala-compile compile compile scala-test-compile test-compile testCompile接着在子项目中引入插件,并配置执行(子项目的pom.xml) org.scala-tools maven-scala-plugin hello com.study.sparkmaven.hello.Hello -Xmx128m -Djava.library.path=...我们此时刷新maven 如果一切正常,此时会有scala的一些操作
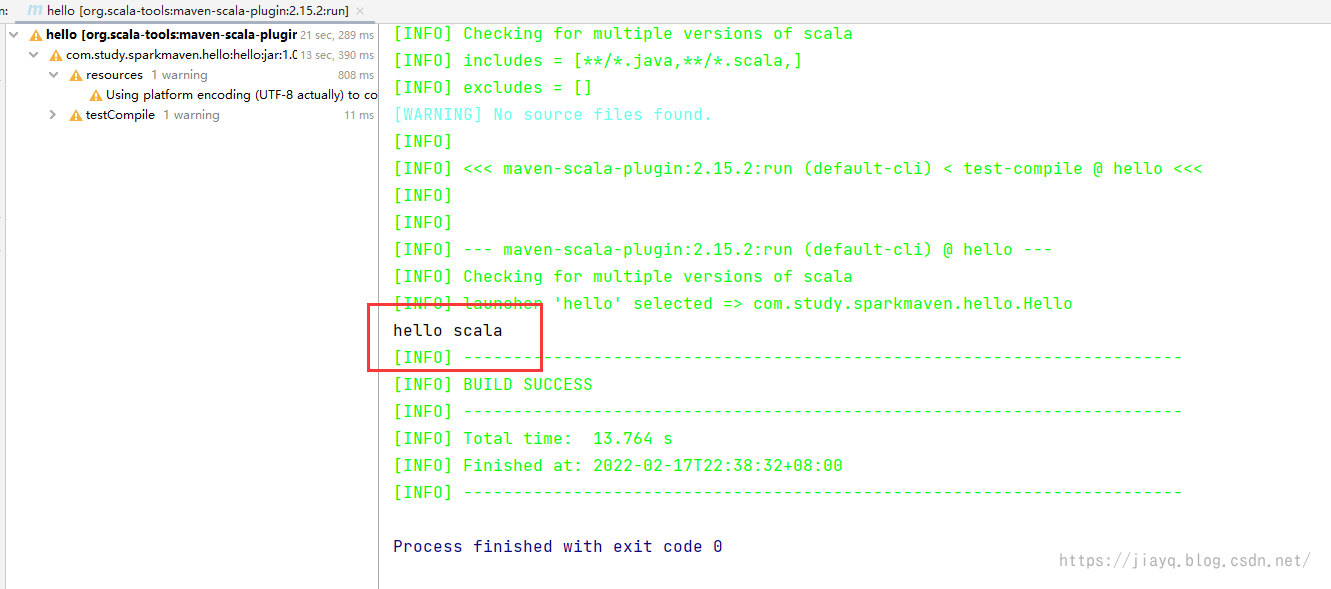
因为我们只配置了一个scala的执行,所以可以直接使用这个run,在只有一个执行的时候,是不需要指定执行的id,如果有多个,不指定执行id,也是会取第一个。 我们双击运行scala:run
第一次会比较慢,因为需要下载依赖。 此时虽然可以运行,但是也是基于idea的,如果我们直接打jar包,并在java环境运行是不行的。 会提示我们没有配置主类
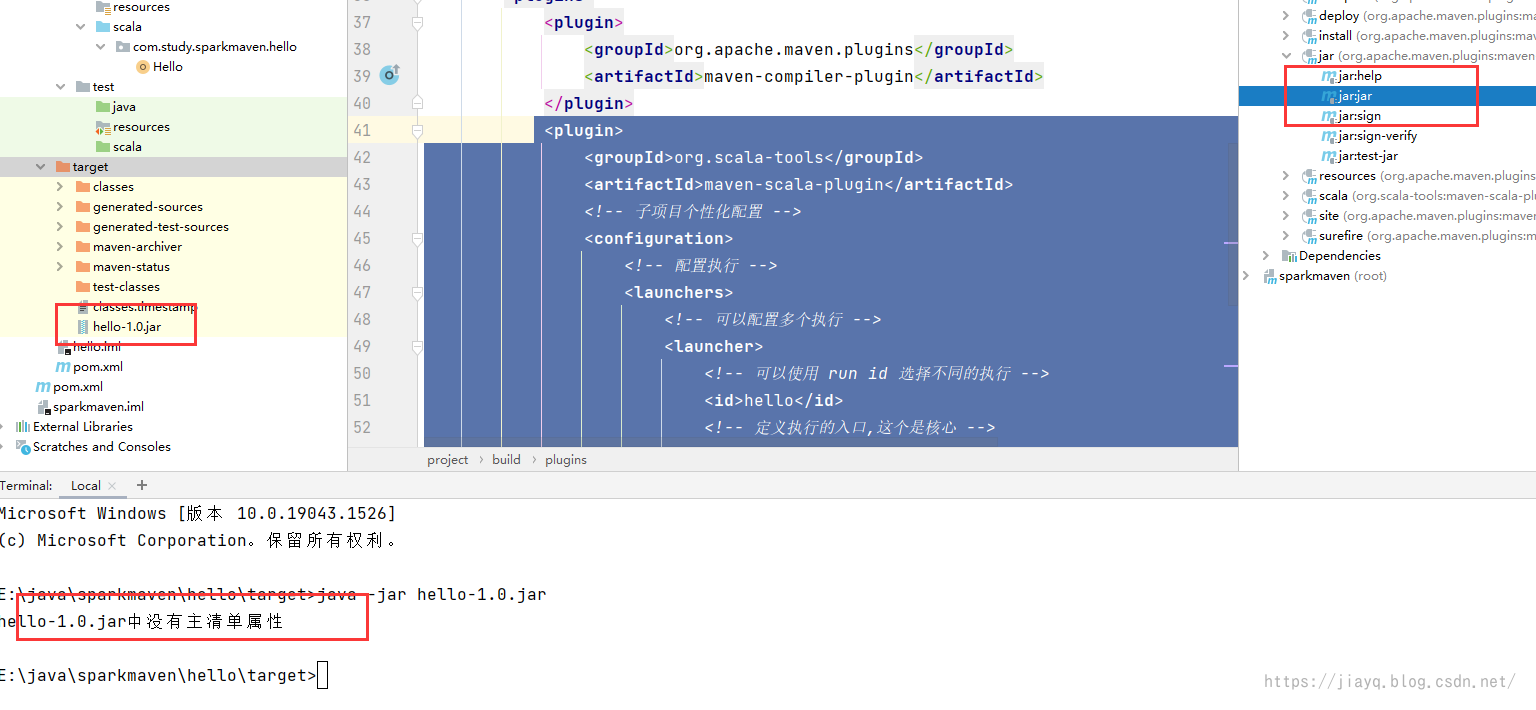
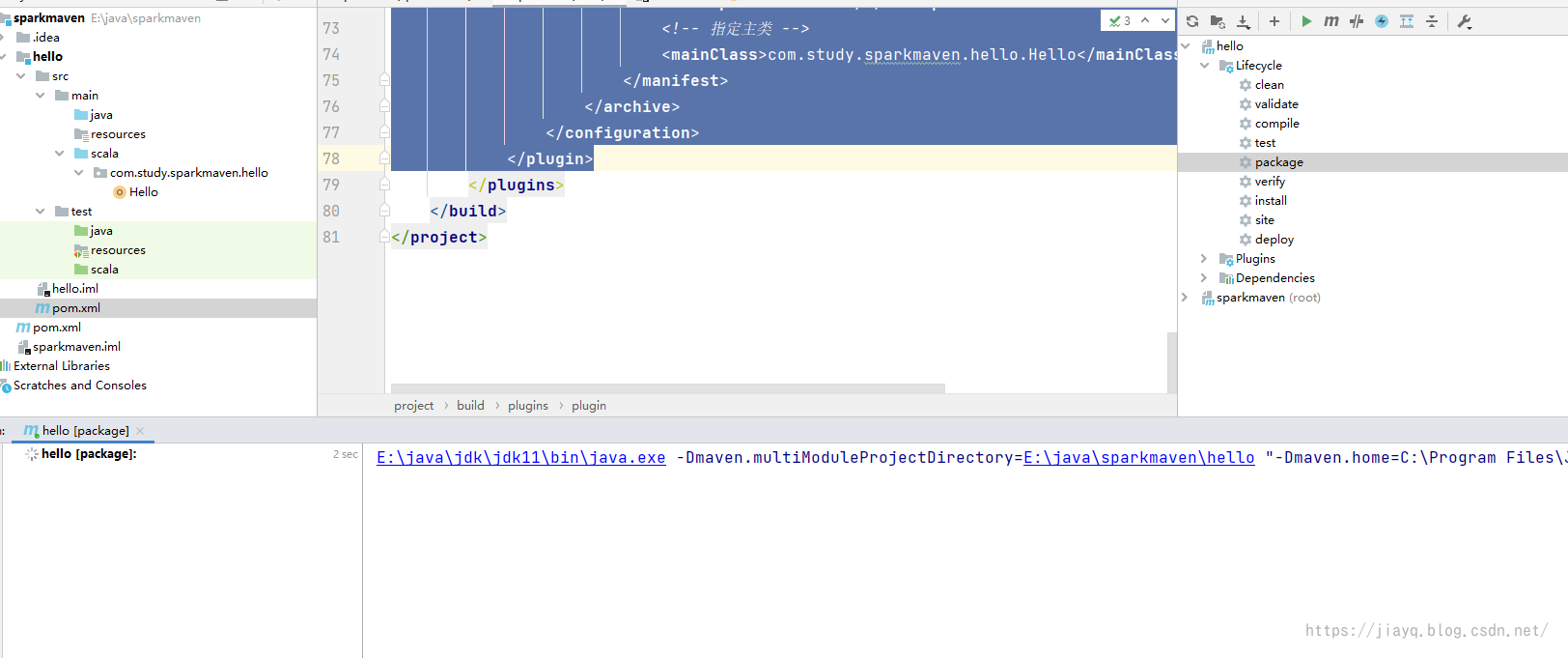
这个插件就是用于指定主类的,打包出来的jar包可以运行 指定版本 3.2.2配置插件 org.apache.maven.plugins maven-jar-plugin ${version.maven.jar.plugin} package jar client子项目中引入 org.apache.maven.plugins maven-jar-plugin true lib/ com.study.sparkmaven.hello.Hello我们刷新项目,并clean后执行package
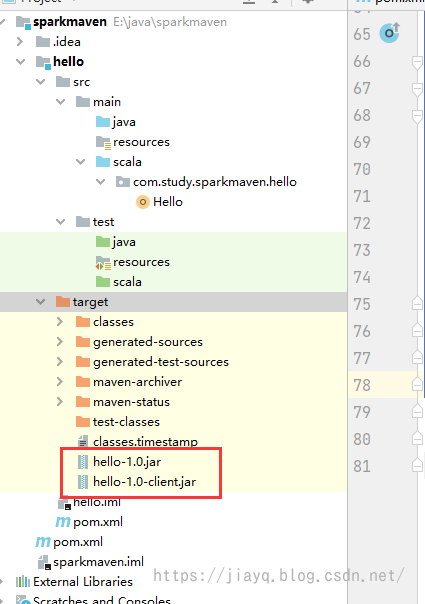
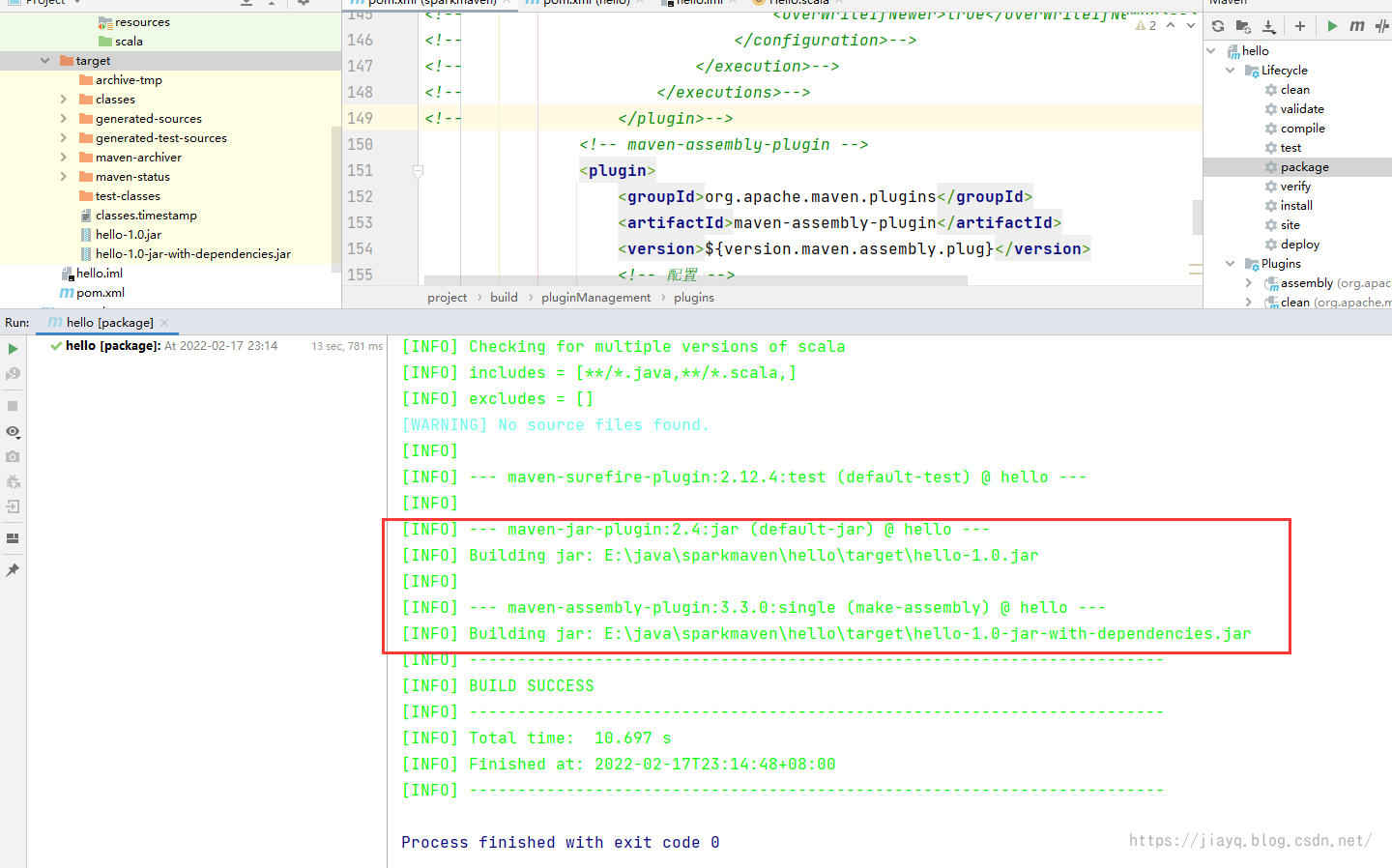
执行后会生成两个jar包
第二个jar包就是插件生成的,尝试执行
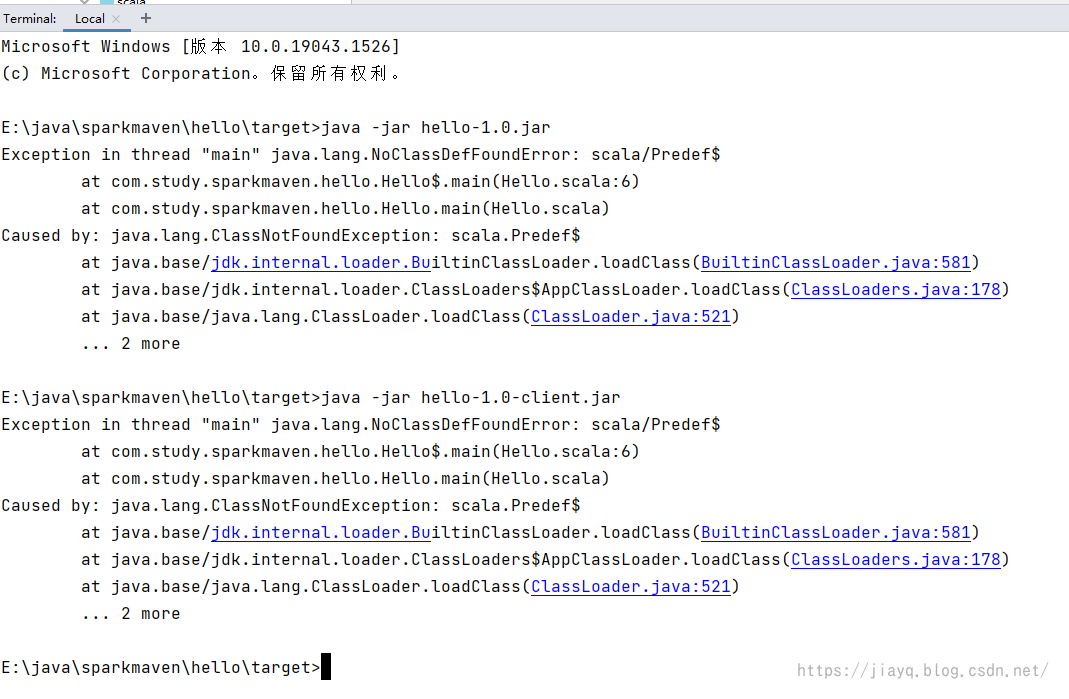
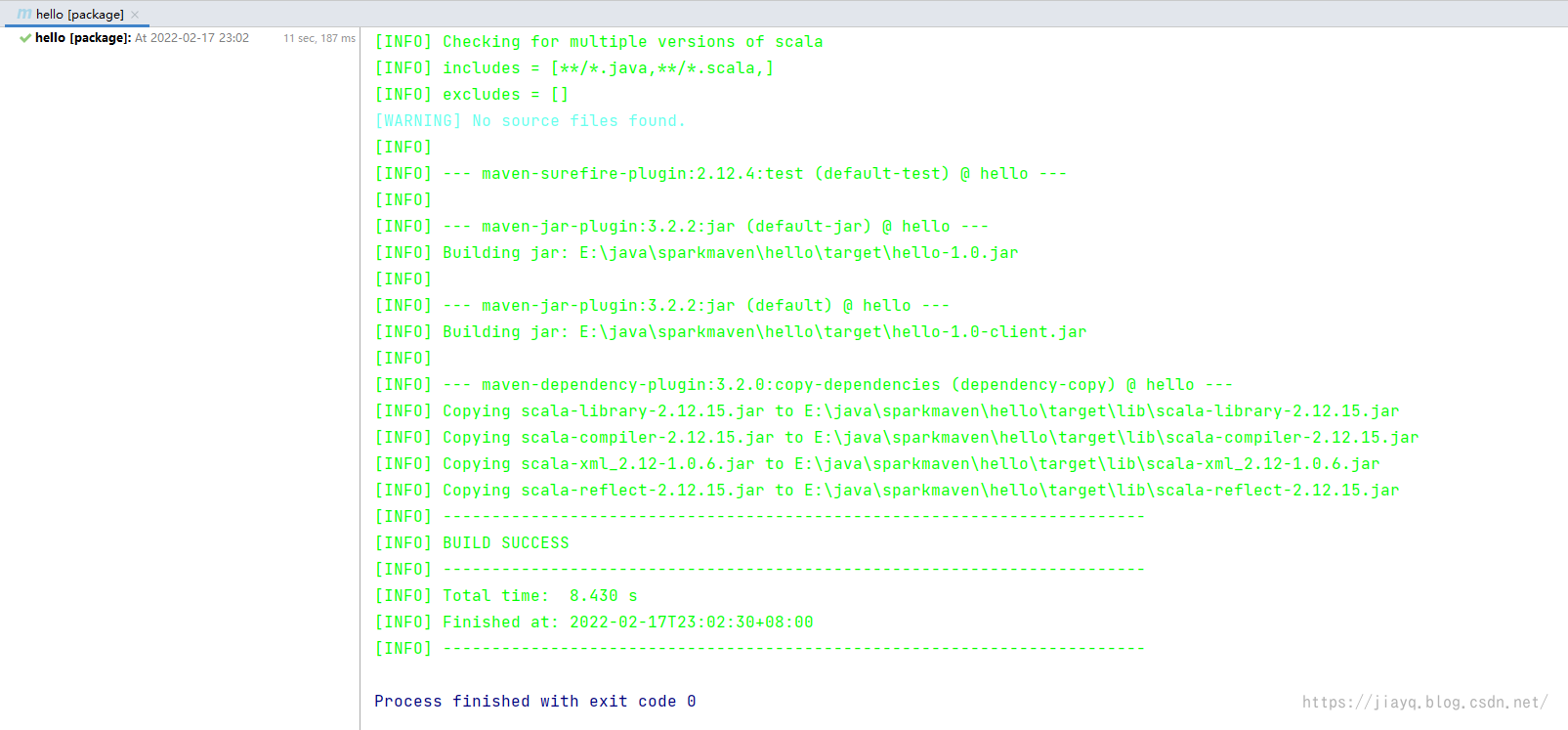
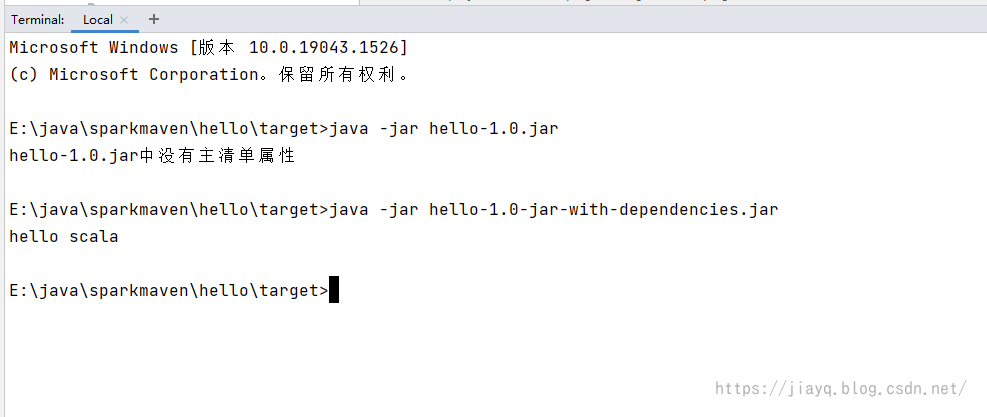
我们依次执行两个jar包,发现还是无法执行,但是至少不是找不到主类的错误了,而是找不到scala的相关库。 这是因为我们虽然指定了依赖在lib目录,但是现在lib目录可是空的。 也就是没有依赖。 此时就需要下面这个插件了。 maven-dependency-plugin依赖拷贝插件,可以将项目的依赖拷贝到指定位置,为打包做准备。 前面我们打包,因为lib目录为空,导致打包的jar中缺少相关的依赖。 我们首先定义版本 3.2.0接着配置插件 org.apache.maven.plugins maven-dependency-plugin ${version.maven.dependency.plugin} dependency-copy package copy-dependencies ${project.build.directory}/lib false false true我们在子项目中引入 org.apache.maven.plugins maven-dependency-plugin因为依赖拷贝算是一个通用的,所以这里把相关的设置放到父项目中的pom.xml中了 刷新maven,先后执行clean和package
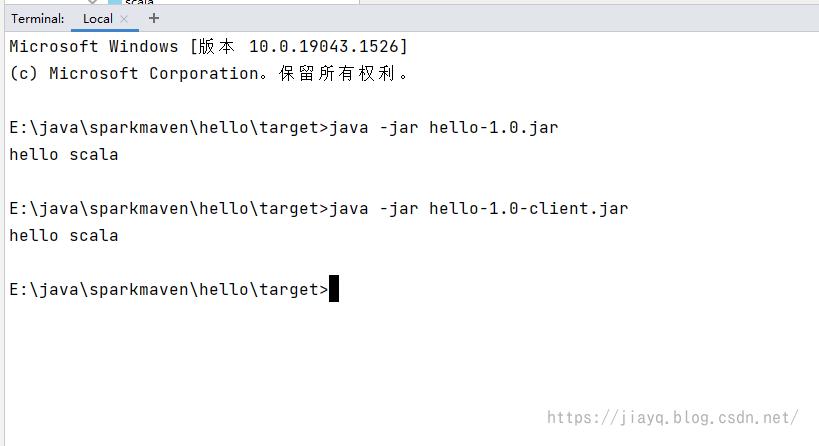
接着尝试执行jar包
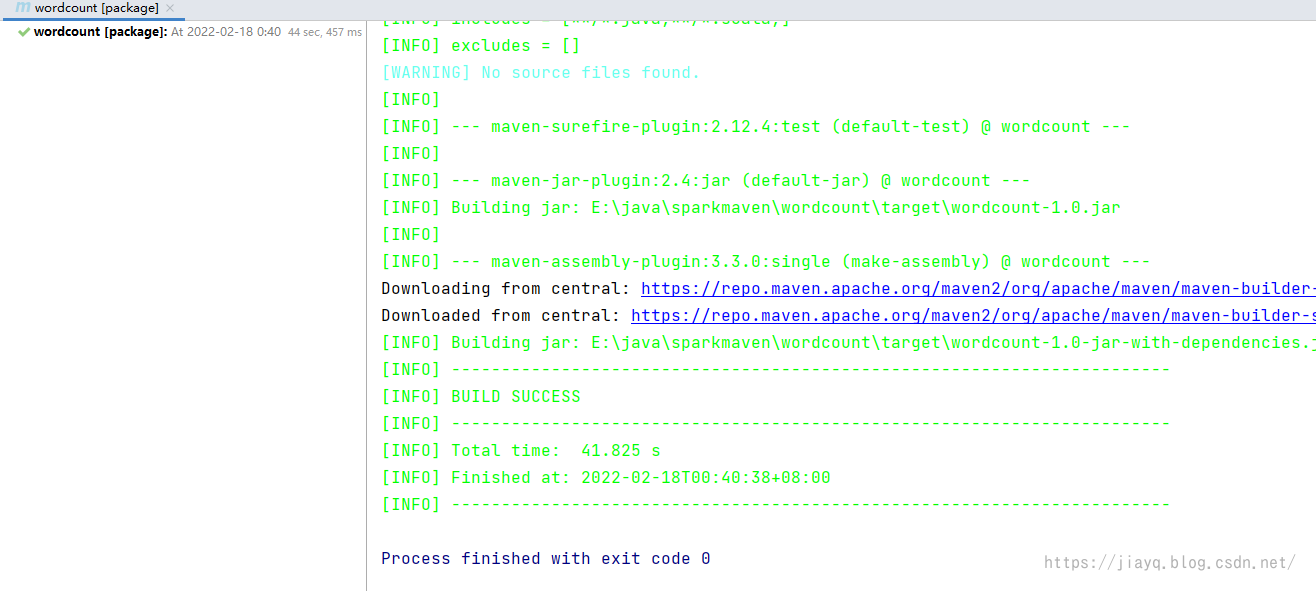
在上面中,实际上是两个插件配合使用,第一个插件用于拷贝依赖,第二个插件用于打包。 但是打包只是能打包jar包,如果你想打war包,或者其他的就不行了。 所以还有一个插件,不仅仅能打jar包,还能打其他的包,而且是集成了这两个插件的功能。 就是大名鼎鼎的assembly插件。 版本定义 3.3.0插件定义 org.apache.maven.plugins maven-assembly-plugin ${version.maven.assembly.plug} jar-with-dependencies make-assembly package single子项目依赖,我们去掉之前的maven-jar-plugin和maven-dependency-plugin插件 org.apache.maven.plugins maven-assembly-plugin true lib/ com.study.sparkmaven.hello.Hello刷新项目并执行clean和package
我们尝试执行
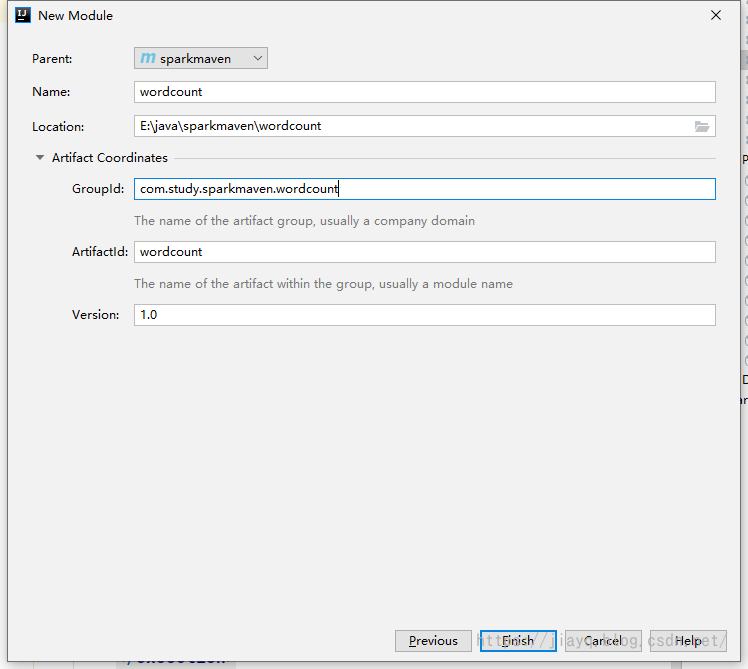
因为我们注释了maven-jar-plugin的配置,所以打包的默认的包是找不到主类的。 而maven-assembly-plugin因为我们配置了主类,而且还启动了依赖拷贝功能,所以打出来的jar不仅仅有主类,还有scala的依赖,可以直接运行。 spark 开发环境我们创建一个空的maven项目
别忘记告诉idea我们需要scala环境
创建目录
包目录
主类
加入spark依赖和scala依赖,以及相关的插件 spark的版本 我在定义properties时遵循一个习惯: 依赖的版本号以.version结尾 插件的版本号以version开头,.plugin结尾 3.2.0增加spark-core_2.12依赖,因为scala二进制不兼容,所以需要注意哦 org.apache.spark spark-core_2.12 ${spark.version}因为spark打的包最终是提交给spark执行的,本身就有spark相关的依赖,所以我们打包的时候不需要将spark的依赖打进去,否则会非常大,而且因为spark本身的依赖关系比较复杂,处理依赖的传递等问题会比较麻烦。 子项目的插件 org.apache.maven.plugins maven-compiler-plugin org.scala-tools maven-scala-plugin wordcount com.study.spark.maven.wordcount.WordCount org.apache.maven.plugins maven-assembly-plugin true lib/ com.study.spark.maven.wordcount.WordCount刷新maven项目后就可以在主类中编写spark代码了 如果你在开发代码的时候,发现scala的相关关键词无法识别,请重新刷新idea的缓存
选择这个重启idea即可
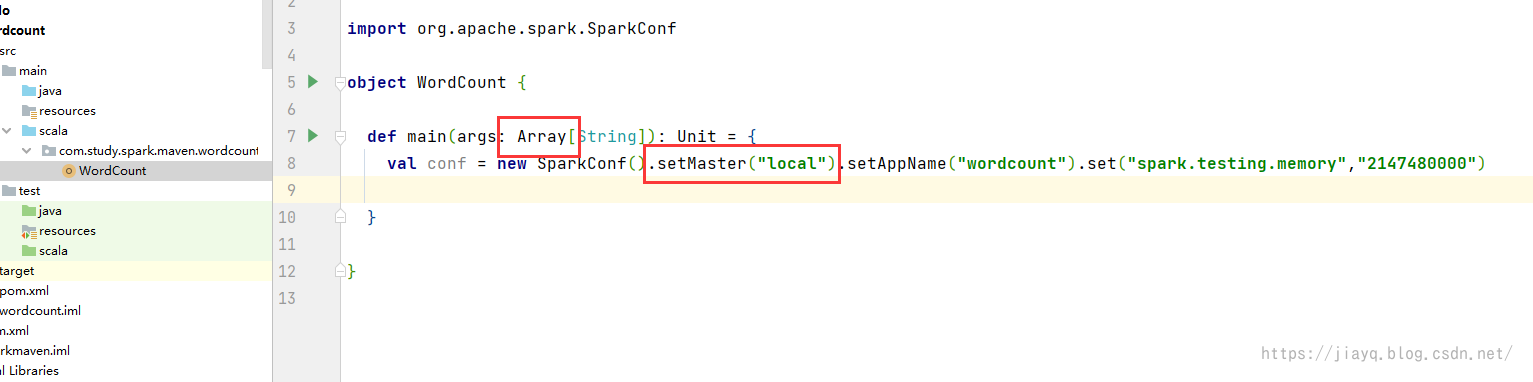
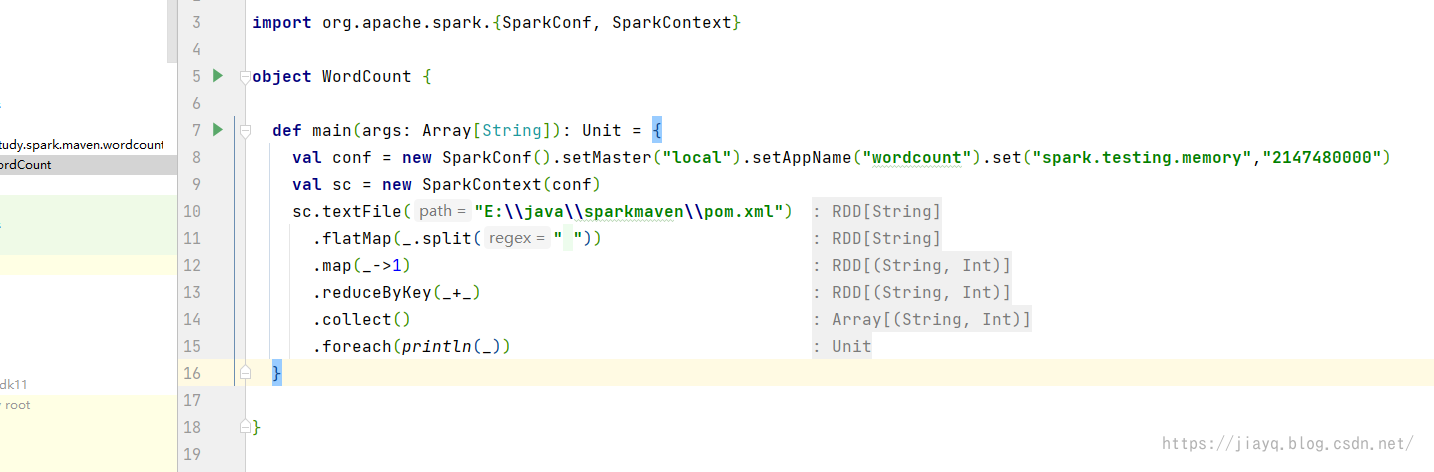
wordcount的代码如下 package com.study.spark.maven.wordcount import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local").setAppName("wordcount").set("spark.testing.memory","2147480000") val sc = new SparkContext(conf) sc.textFile("E:\\java\\sparkmaven\\pom.xml") .flatMap(_.split(" ")) .map(_->1) .reduceByKey(_+_) .collect() .foreach(println(_)) } }
我们首先直接点击运行
接着使用scala:run执行
接着放开spark-core的scope注释,进行打包 第一次运行会比较慢,而且我们基本上都是用的最新的spark的依赖,镜像库可能还没有同步,所以更慢。
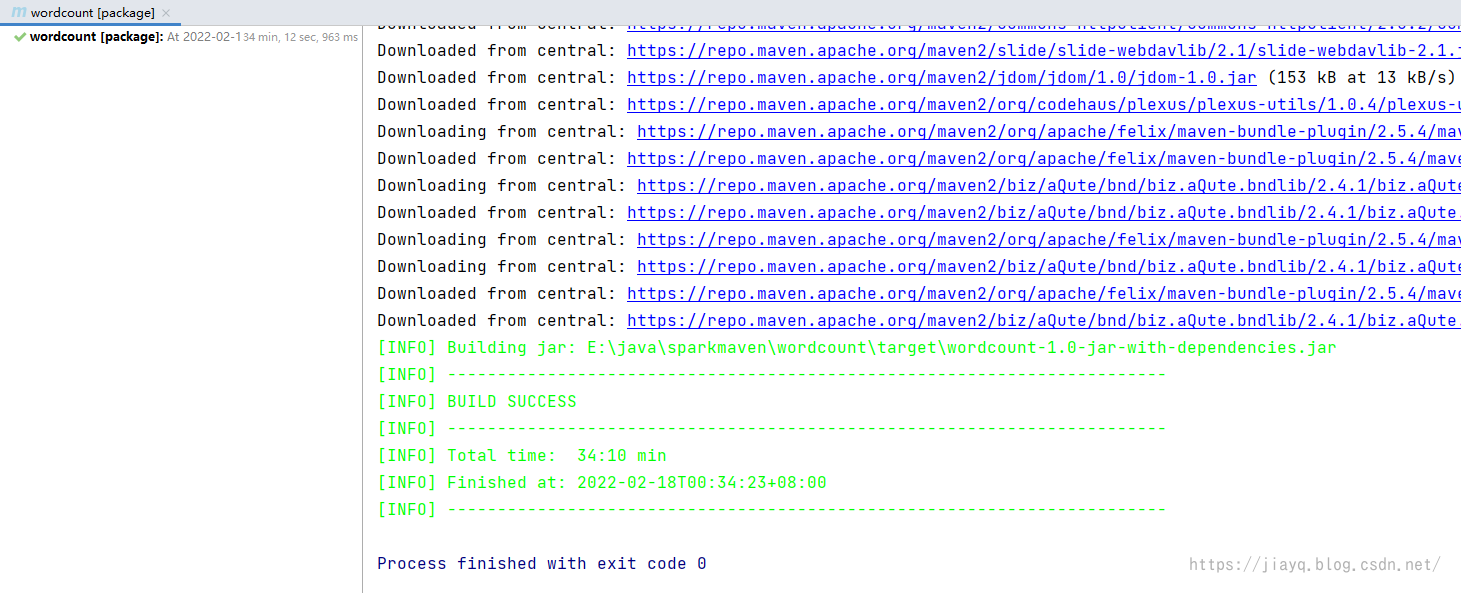
30多分钟,我是楞是等它结束了
看看打的包能不能运行
也是可以运行的
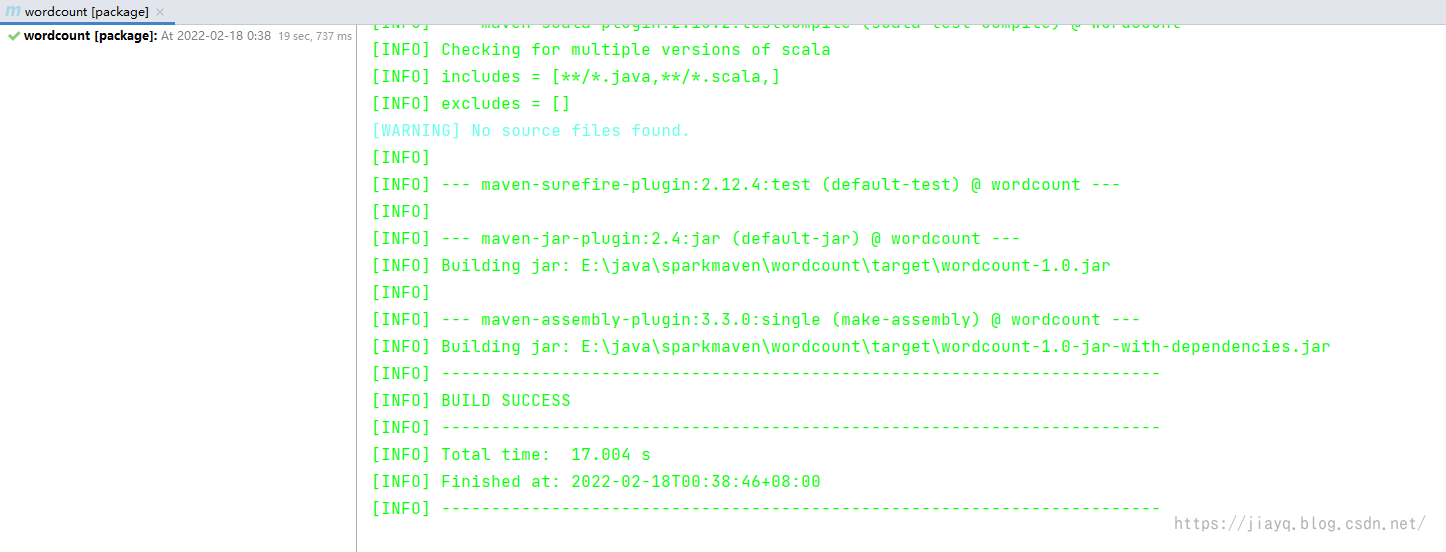
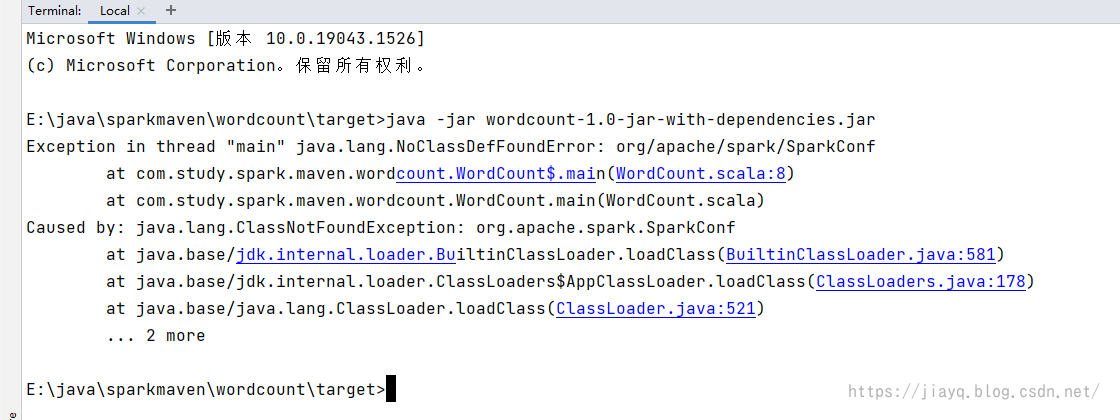
maven-assembly-plugin活生生的把spark打包打进去了 如果我们不需要将spark打包,那么应该会快很多的
不过会提示找不到spark的类
不过第二次打包就会快很多了
而且不管我们有没有把spark的依赖打包,提交给spark执行一般不会有问题。 但是需要注意jar包内的spark和spark环境的版本之间可能会存在冲突,所以不建议把spark的依赖进行打包。 我们尝试把打的jar包,提交到spark集群中运行 首先启动集群环境
然后使用xshell链接(家庭版免费)
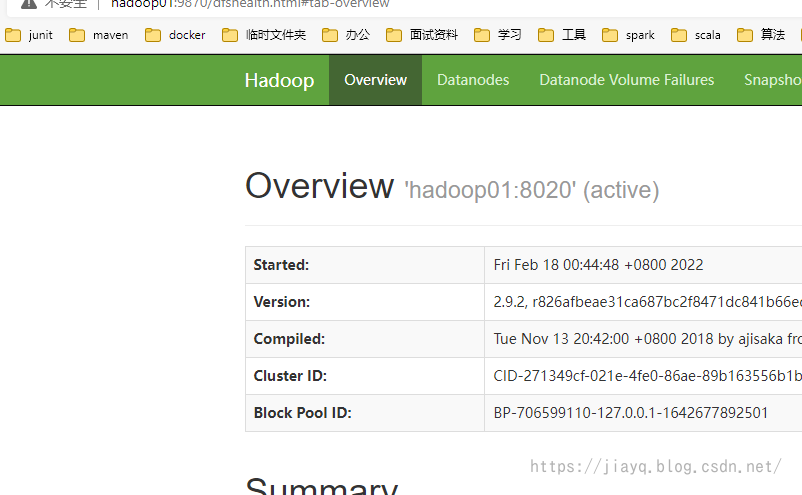
启动hdfs集群
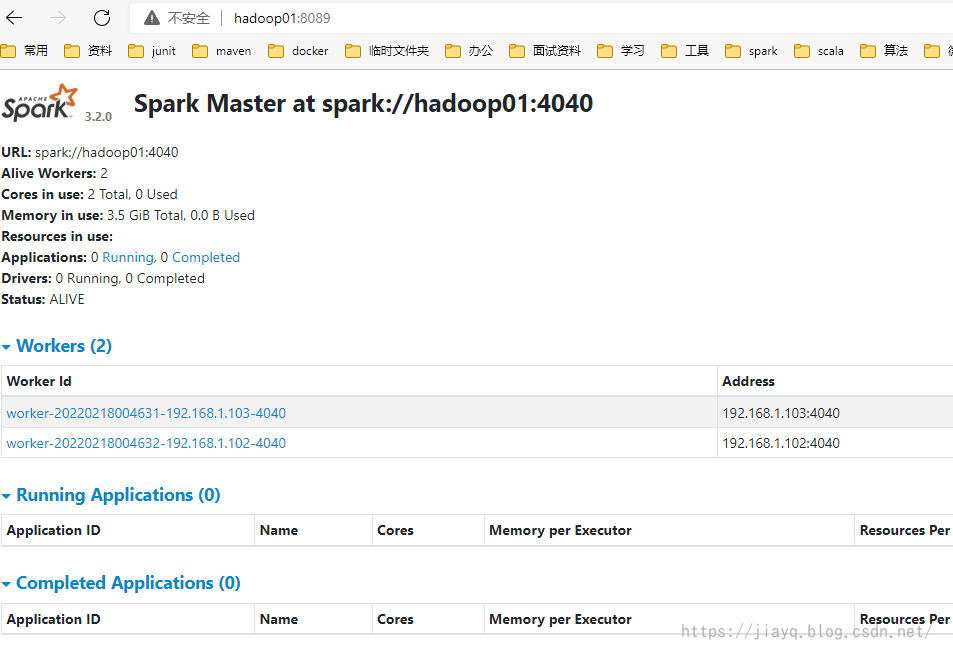
接着启动spark集群
启动spark历史记录服务
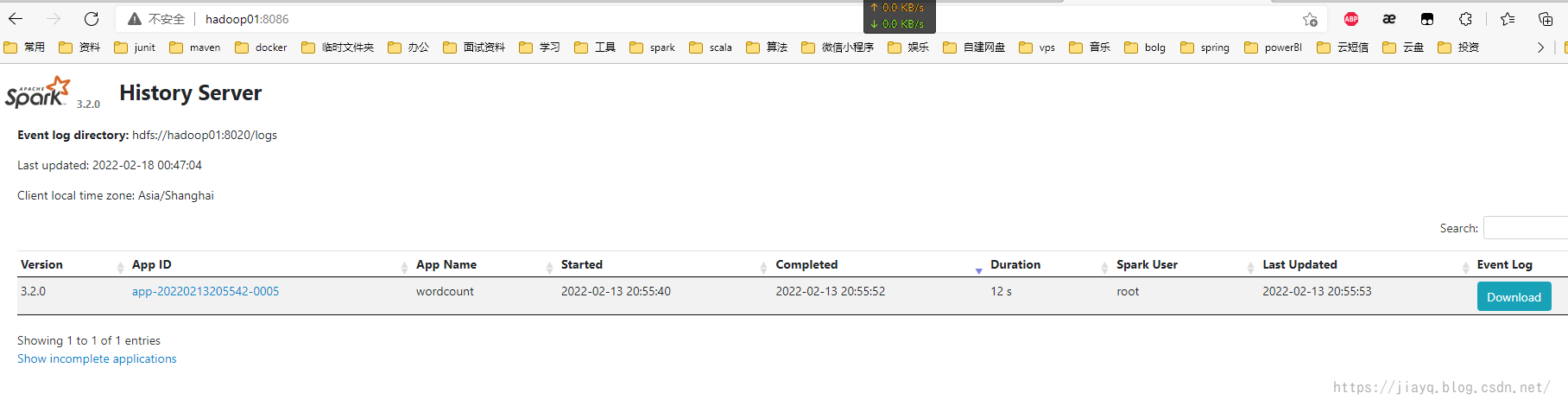
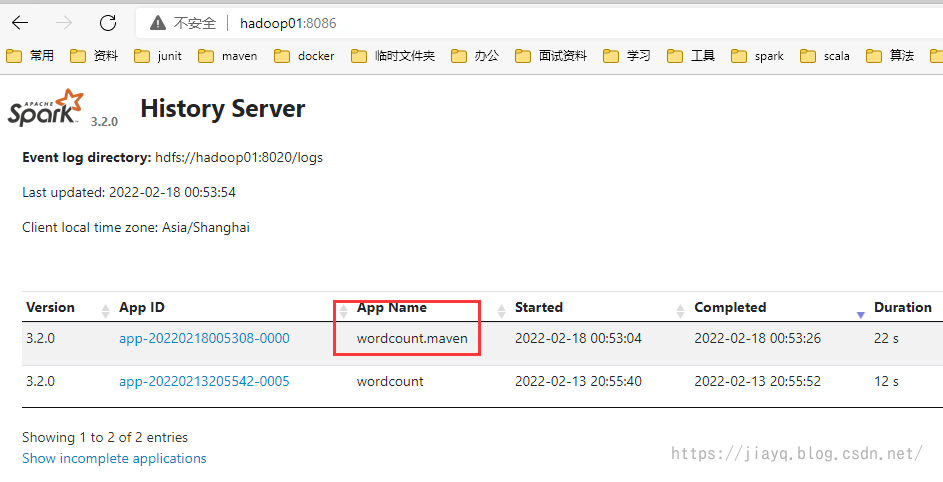
这个wordcount是在sbt构建中执行的,详见spark源码编译和集群部署以及idea中sbt开发环境集成_a18792721831的博客-CSDN博客 因为我们的hdfs上面已经有文件了,所以需要修改代码,使用hdfs的文件,而不是本地的文件,而且使用集群的spark而不是本地的spark 修改后的WordCount如下 package com.study.spark.maven.wordcount import org.apache.spark.{SparkConf, SparkContext} object WordCount { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("spark://hadoop01:4040").setAppName("wordcount.maven") val sc = new SparkContext(conf) sc.textFile("hdfs://hadoop01:8020/input/build.sbt") .flatMap(_.split(" ")) .map(_->1) .reduceByKey(_+_) .collect() .foreach(println(_)) } }打包并将jar包上传到服务器,我们不需要spark的依赖
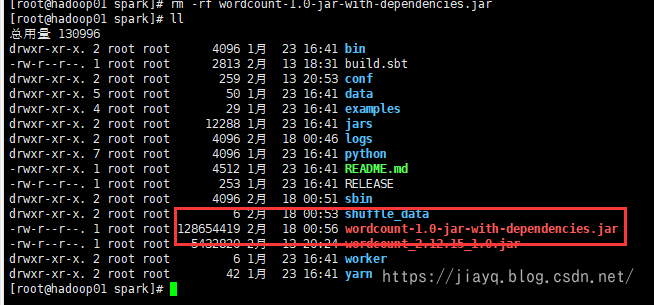
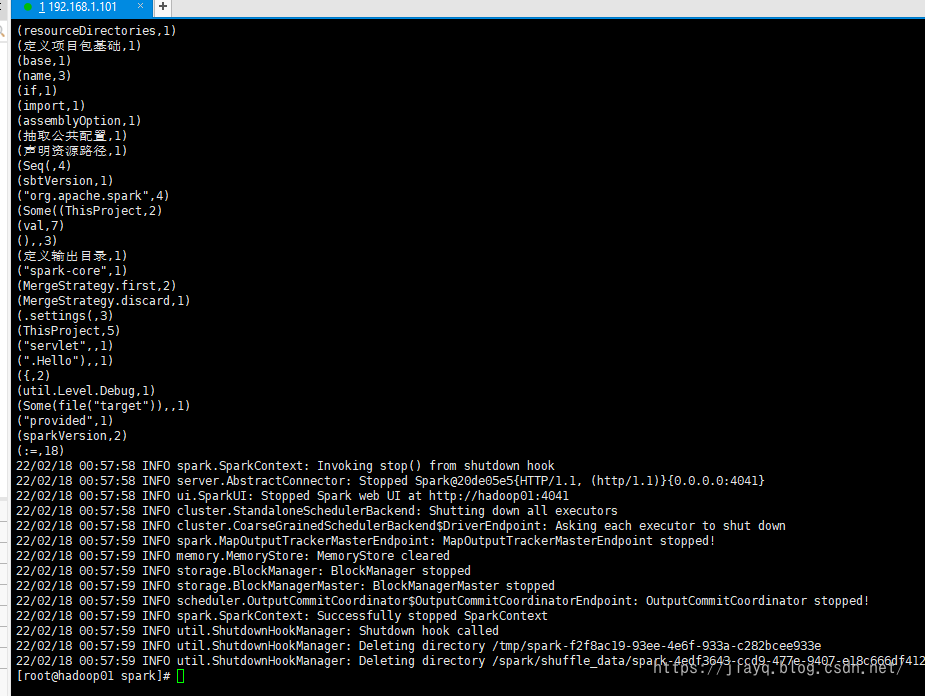
使用如下命令提交 spark-submit --class com.study.spark.maven.wordcount.WordCount --master spark://hadoop01:4040 wordcount-1.0-jar-with-dependencies.jar成功执行
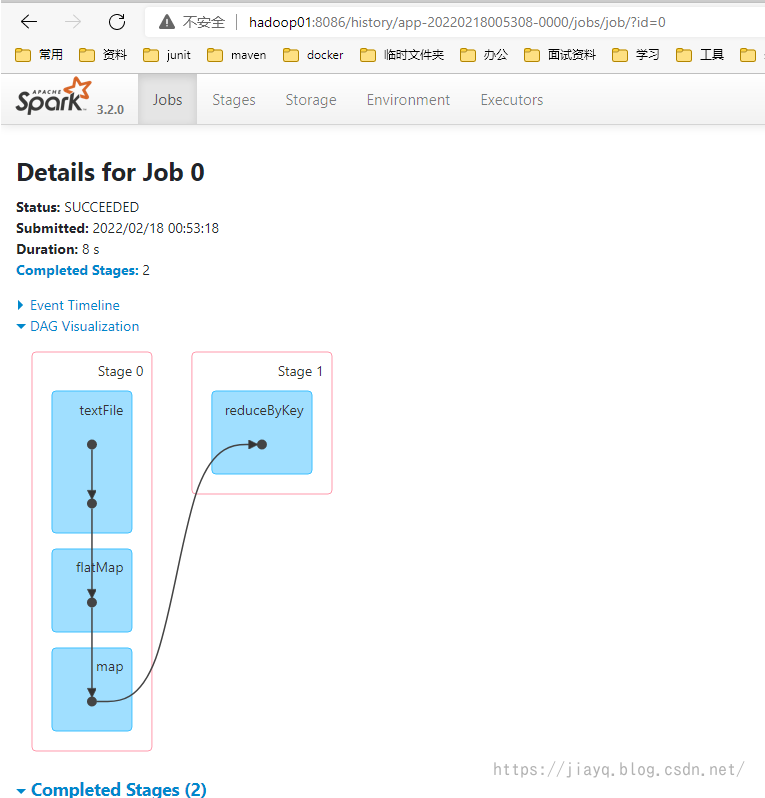
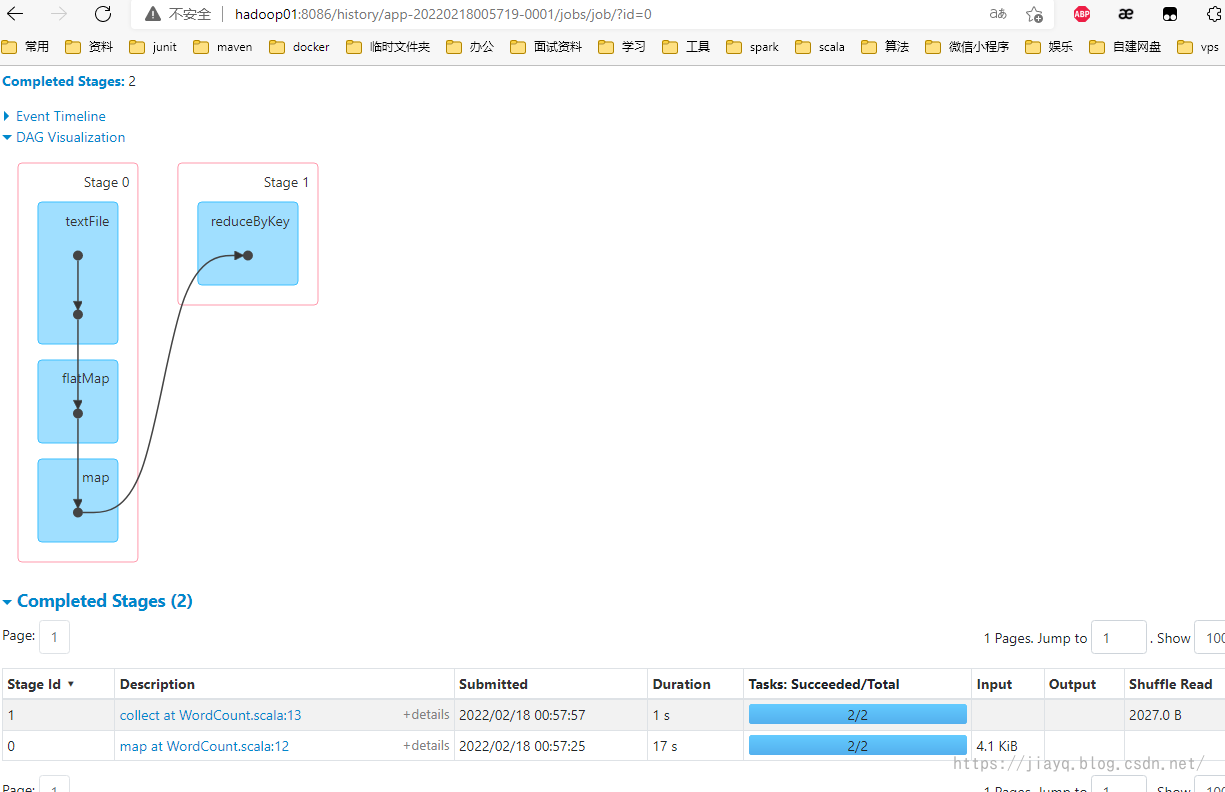
从spark历史记录中也能查看
其实我也有个疑问,如果我们把spark的依赖打包了,还能执行吗? 试试! 含有spark依赖的包,128M,😆
执行:
没啥区别
这是因为我服务器也是3.2.0版本,而且是使用最新的源码编译的,详见spark源码编译和集群部署以及idea中sbt开发环境集成_a18792721831的博客-CSDN博客,本地的依赖也是3.2.0,所以jar包中有没有spark依赖都是可以的。 如果你无法准确的知道服务器的spark的版本,以及服务器的spark的scala版本,建议还是不要把spark依赖打包。 |




【本文地址】
今日新闻 |
推荐新闻 |